









һ��Ԕ��Flink֪�R�wϵ
�ġ�Flink ���Ӵ�ȫ
Flink��Spark���,Ҳ��һ�Nһվʽ̎���Ŀ��;�ȿ����M(j��n)����̎��(DataSet),Ҳ�����M(j��n)�Ќ�(sh��)�r(sh��)̎��(DataStream)��
�������挢Flink�����ӷ֞�ɴ��:һ���DataSet,һ���DataStream��
DataSet ��̎������һ��Source����1�� fromCollection
fromCollection:�ı��ؼ����xȡ��(sh��)��(j��)
��:
val env = ExecutionEnvironment��getExecutionEnvironment
val textDataSet: DataSet[String] = env��fromCollection(
List("1,����", "2,����", "3,����", "4,�w��")
)
2�� readTextFile
readTextFile:���ļ����xȡ
val textDataSet: DataSet[String] = env��readTextFile("/data/a��txt")
3�� readTextFile:��vĿ�
readTextFile���Ԍ�һ���ļ�Ŀ䛃�(n��i)�������ļ�,����������Ŀ��е������ļ��ı�v�L����ʽ
val parameters = new Configuration
// recursive��file��enumeration �_���f�w
parameters��setBoolean("recursive��file��enumeration", true)
val file = env��readTextFile("/data")��withParameters(parameters)
4�� readTextFile:�xȡ���s�ļ�
���������s���,����Ҫָ���κ��~���inputformat����,flink�����Ԅ��R�e���ҽ≺������,���s�ļ����ܲ��������xȡ,����������xȡ��,�@�ӿ��ܕ�Ӱ����I(y��)�Ŀ���s�ԡ�
���s�����ļ��U(ku��)չ���Ƿ�ɲ����xȡDEFLATE��deflatenoGZip��gz ��gzipnoBzip2��bz2noXZ��xznoval file = env��readTextFile("/data/file��gz")
����Transform�D(zhu��n)�Q����
��?y��n)�Transform���ӻ���Source���Ӳ���,�������Ș�(g��u)��Flink��(zh��)�Эh(hu��n)����Source����,���m(x��)Transform���Ӳ������ڴ�:
val env = ExecutionEnvironment��getExecutionEnvironment
val textDataSet: DataSet[String] = env��fromCollection(
List("����,1", "����,2", "����,3", "����,4")
)
1�� map
��DataSet�е�ÿһ��Ԫ���D(zhu��n)�Q������һ��Ԫ��
// ʹ��map��List�D(zhu��n)�Q��һ��Scala�Ę����
case class User(name: String, id: String)
val userDataSet: DataSet[User] = textDataSet��map {
text =>
val fieldArr = text��split(",")
User(fieldArr(0), fieldArr(1))
}
userDataSet��print()
2�� flatMap
��DataSet�е�ÿһ��Ԫ���D(zhu��n)�Q��0������n��Ԫ�ء�
// ʹ��flatMap����,�������еĔ�(sh��)��(j��):
// ����(j��)��һ��Ԫ��,�M(j��n)�зֽM
// ����(j��)�ڶ���Ԫ��,�M(j��n)�оۺ���ֵ
val result = textDataSet��flatMap(line => line)
��groupBy(0) // ����(j��)��һ��Ԫ��,�M(j��n)�зֽM
��sum(1) // ����(j��)�ڶ���Ԫ��,�M(j��n)�оۺ���ֵ
result��print()
3�� mapPartition
��һ���օ^(q��)�е�Ԫ���D(zhu��n)�Q����һ��Ԫ��
// ʹ��mapPartition����,��List�D(zhu��n)�Q��һ��scala�Ę����
case class User(name: String, id: String)
val result: DataSet[User] = textDataSet��mapPartition(line => {
line��map(index => User(index��_1, index��_2))
})
result��print()
4�� filter
�^�V����һЩ���ϗl����Ԫ��,����booleanֵ��true��Ԫ��
val source: DataSet[String] = env��fromElements("java", "scala", "java")
val filter:DataSet[String] = source��filter(line => line��contains("java"))//�^�V����java�Ĕ�(sh��)��(j��)
filter��print()
5�� reduce
���Ԍ�һ��dataset����һ��group���M(j��n)�оۺ�Ӌ(j��)��,��K�ۺϳ�һ��Ԫ��
// ʹ�� fromElements ��(g��u)����(sh��)��(j��)Դ
val source = env��fromElements(("java", 1), ("scala", 1), ("java", 1))
// ʹ��map�D(zhu��n)�Q��DataSetԪ�M
val mapData: DataSet[(String, Int)] = source��map(line => line)
// ����(j��)�ׂ�Ԫ�طֽM
val groupData = mapData��groupBy(_��_1)
// ʹ��reduce�ۺ�
val reduceData = groupData��reduce((x, y) => (x��_1, x��_2 + y��_2))
// ��ӡ�yԇ
reduceData��print()
6�� reduceGroup
��һ��dataset����һ��group�ۺϳ�һ�������Ԫ�ء�
reduceGroup��reduce��һ�N��(y��u)������;
�����ȷֽMreduce,Ȼ���������w��reduce;�@�����ĺ�̎���ǿ��Ԝp�پW(w��ng)�j(lu��)IO
// ʹ�� fromElements ��(g��u)����(sh��)��(j��)Դ
val source: DataSet[(String, Int)] = env��fromElements(("java", 1), ("scala", 1), ("java", 1))
// ����(j��)�ׂ�Ԫ�طֽM
val groupData = source��groupBy(_��_1)
// ʹ��reduceGroup�ۺ�
val result: DataSet[(String, Int)] = groupData��reduceGroup {
(in: Iterator[(String, Int)], out: Collector[(String, Int)]) =>
val tuple = in��reduce((x, y) => (x��_1, x��_2 + y��_2))
out��collect(tuple)
}
// ��ӡ�yԇ
result��print()
7�� minBy��maxBy
�x�������Сֵ�����ֵ��Ԫ��
// ʹ��minBy����,��List��ÿ���˵���Сֵ
// List("����,1", "����,2", "����,3", "����,4")
case class User(name: String, id: String)
// ��List�D(zhu��n)�Q��һ��scala�Ę����
val text: DataSet[User] = textDataSet��mapPartition(line => {
line��map(index => User(index��_1, index��_2))
})
val result = text
��groupBy(0) // ���������ֽM
��minBy(1) // ÿ���˵���Сֵ
8�� Aggregate
�ڔ�(sh��)��(j��)�����M(j��n)�оۺ�����ֵ(���ֵ����Сֵ)
val data = new mutable��MutableList[(Int, String, Double)]
data��+=((1, "yuwen", 89��0))
data��+=((2, "shuxue", 92��2))
data��+=((3, "yuwen", 89��99))
// ʹ�� fromElements ��(g��u)����(sh��)��(j��)Դ
val input: DataSet[(Int, String, Double)] = env��fromCollection(data)
// ʹ��group��(zh��)�зֽM����
val value = input��groupBy(1)
// ʹ��aggregate�����ֵԪ��
��a(ch��n)ggregate(Aggregations��MAX, 2)
// ��ӡ�yԇ
value��print()
Aggregateֻ��������Ԫ�M��
ע��:
Ҫʹ��aggregate,ֻ��ʹ���ֶ����������������Q���M(j��n)�зֽM groupBy(0) ,��t����(b��o)һ���e�`:
Exception in thread "main" java��lang��UnsupportedOperationException: Aggregate does not supportgrouping with KeySelector functions, yet��
9�� distinct
ȥ���؏�(f��)�Ĕ�(sh��)��(j��)
// ��(sh��)��(j��)Դʹ����һ�}��
// ʹ��distinct����,����(j��)��Ŀȥ���������؏�(f��)��Ԫ�M��(sh��)��(j��)
val value: DataSet[(Int, String, Double)] = input��distinct(1)
value��print()
10�� first
ȡǰN����(sh��)
input��first(2) // ȡǰ�ɂ���(sh��)
11�� join
���ɂ�DataSet����һ���l���B�ӵ�һ��,�γ��µ�DataSet
// s1 �� s2 ��(sh��)��(j��)����ʽ����:
// DataSet[(Int, String,String, Double)]
val joinData = s1��join(s2) // s1��(sh��)��(j��)�� join s2��(sh��)��(j��)��
��where(0)��equalTo(0) { // join�ėl��
(s1, s2) => (s1��_1, s1��_2, s2��_2, s1��_3)
}
12�� leftOuterJoin
�����B��,��߅��Dataset�е�ÿһ��Ԫ��,ȥ�B����߅��Ԫ��
����߀��:
rightOuterJoin:�����B��,��߅��Dataset�е�ÿһ��Ԫ��,ȥ�B����߅��Ԫ��
fullOuterJoin:ȫ���B��,���҃�߅��Ԫ��,ȫ���B��
������ leftOuterJoin �M(j��n)��ʾ��:
val data1 = ListBuffer[Tuple2[Int,String]]()
data1��a(ch��n)ppend((1,"zhangsan"))
data1��a(ch��n)ppend((2,"lisi"))
data1��a(ch��n)ppend((3,"wangwu"))
data1��a(ch��n)ppend((4,"zhaoliu"))
val data2 = ListBuffer[Tuple2[Int,String]]()
data2��a(ch��n)ppend((1,"beijing"))
data2��a(ch��n)ppend((2,"shanghai"))
data2��a(ch��n)ppend((4,"guangzhou"))
val text1 = env��fromCollection(data1)
val text2 = env��fromCollection(data2)
text1��leftOuterJoin(text2)��where(0)��equalTo(0)��a(ch��n)pply((first,second)=>{
if(second==null){
(first��_1,first��_2,"null")
}else{
(first��_1,first��_2,second��_2)
}
})��print()
13�� cross
�������,ͨ�^�γ��@����(sh��)��(j��)����������(sh��)��(j��)���ĵѿ����e,��(chu��ng)��һ���µĔ�(sh��)��(j��)��
��join���,�����@�N����������a(ch��n)���ѿ����e,�ڔ�(sh��)��(j��)���^��ĕr(sh��)��,�Ƿdz����ă�(n��i)��IJ���
val cross = input1��cross(input2){
(input1 , input2) => (input1��_1,input1��_2,input1��_3,input2��_2)
}
cross��print()
14�� union
(li��n)�ϲ���,��(chu��ng)����������ԓ��(sh��)��(j��)����������(sh��)��(j��)����Ԫ�ص���(sh��)��(j��)��,����ȥ��
val unionData: DataSet[String] = elements1��union(elements2)��union(elements3)
// ȥ���؏�(f��)��(sh��)��(j��)
val value = unionData��distinct(line => line)
15�� rebalance
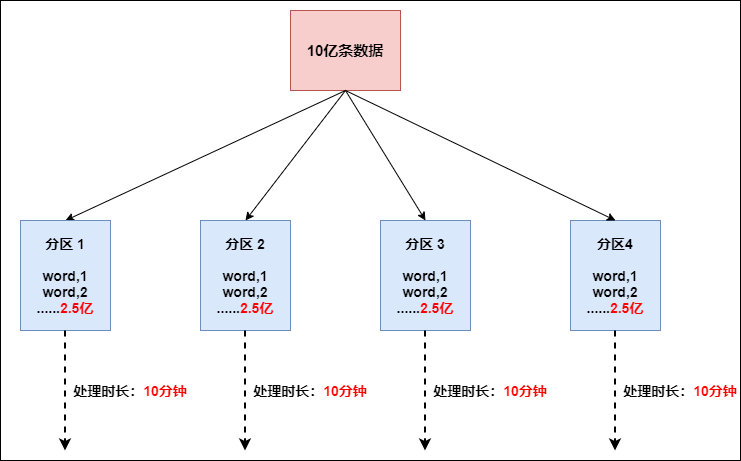
FlinkҲ�Д�(sh��)��(j��)�Aб�ĕr(sh��)��,���箔(d��ng)ǰ�Д�(sh��)��(j��)�����10�|�l��(sh��)��(j��)��Ҫ̎��,��̎���^���п��ܕ��l(f��)����D��ʾ�Ġ�r:

�@���r(sh��)�����w��(sh��)��(j��)��ֻ��Ҫ10��犽�Q�Ć��},���F(xi��n)�˔�(sh��)��(j��)�Aб,�C(j��)��1�ϵ��΄�(w��)��Ҫ4��С�r(sh��)�������,��ô����3�_�C(j��)����(zh��)���ꮅҲҪ�ȴ��C(j��)��1��(zh��)���ꮅ��������w���΄�(w��)���;�����ڌ�(sh��)�H�Ĺ�����,���F(xi��n)�@�N��r���^�õĽ�Q�������ǽ���Ҫ��B�ġ�rebalance(��(n��i)��ʹ��round robin��������(sh��)��(j��)�����ɢ���@���ڔ�(sh��)��(j��)�Aб�r(sh��)�Ǻܺõ��x��)
// ʹ��rebalance����,���┵(sh��)��(j��)�Aб
val rebalance = filterData��rebalance()
16�� partitionByHash
����ָ����key�M(j��n)��hash�օ^(q��)
val data = new mutable��MutableList[(Int, Long, String)]
data��+=((1, 1L, "Hi"))
data��+=((2, 2L, "Hello"))
data��+=((3, 2L, "Hello world"))
val collection = env��fromCollection(data)
val unique = collection��partitionByHash(1)��mapPartition{
line =>
line��map(x => (x��_1 , x��_2 , x��_3))
}
unique��writeAsText("hashPartition", WriteMode��NO_OVERWRITE)
env��execute()
17�� partitionByRange
����(j��)ָ����key����(sh��)��(j��)���M(j��n)�з����օ^(q��)
val data = new mutable��MutableList[(Int, Long, String)]
data��+=((1, 1L, "Hi"))
data��+=((2, 2L, "Hello"))
data��+=((3, 2L, "Hello world"))
data��+=((4, 3L, "Hello world, how are you?"))
val collection = env��fromCollection(data)
val unique = collection��partitionByRange(x => x��_1)��mapPartition(line => line��map{
x=>
(x��_1 , x��_2 , x��_3)
})
unique��writeAsText("rangePartition", WriteMode��OVERWRITE)
env��execute()
18�� sortPartition
����(j��)ָ�����ֶ�ֵ�M(j��n)�зօ^(q��)������
val data = new mutable��MutableList[(Int, Long, String)]
data��+=((1, 1L, "Hi"))
data��+=((2, 2L, "Hello"))
data��+=((3, 2L, "Hello world"))
data��+=((4, 3L, "Hello world, how are you?"))
val ds = env��fromCollection(data)
val result = ds
��map { x => x }��setParallelism(2)
��sortPartition(1, Order��DESCENDING)//��һ������(sh��)���������Ă��ֶ��M(j��n)�зօ^(q��)
��mapPartition(line => line)
��collect()
println(result)
����Sink����1�� collect
����(sh��)��(j��)ݔ�������ؼ���
result��collect()
2�� writeAsText
����(sh��)��(j��)ݔ�����ļ�
Flink֧�ֶ�N�惦�O(sh��)���ϵ��ļ�,���������ļ�,hdfs�ļ���
Flink֧�ֶ�N�ļ��Ĵ惦��ʽ,����text�ļ�,CSV�ļ���
// ����(sh��)��(j��)���뱾���ļ�
result��writeAsText("/data/a", WriteMode��OVERWRITE)
// ����(sh��)��(j��)����HDFS
result��writeAsText("hdfs://node01:9000/data/a", WriteMode��OVERWRITE)
DataStream��̎������
��DataSetһ��,DataStreamҲ����һϵ�е�Transformation����
һ��Source����
Flink����ʹ�� StreamExecutionEnvironment��a(ch��n)ddSource(source) ����҂��ij������Ӕ�(sh��)��(j��)��Դ��
Flink �ѽ�(j��ng)�ṩ�����Ɍ�(sh��)�F(xi��n)���˵� source functions,��(d��ng)Ȼ�҂�Ҳ����ͨ�^��(sh��)�F(xi��n) SourceFunction ���Զ��x�Dz��е�source���ߌ�(sh��)�F(xi��n) ParallelSourceFunction �ӿڻ��ߔU(ku��)չ RichParallelSourceFunction ���Զ��x���е� source��
Flink����̎���ϵ�source������̎���ϵ�source����һ�¡�������4���:
���ڱ��ؼ��ϵ�source(Collection-based-source)�����ļ���source(File-based-source)- �xȡ�ı��ļ�,������ TextInputFormat Ҏ(gu��)�����ļ�,�����������ַ������ػ��ھW(w��ng)�j(lu��)���ֵ�source(Socket-based-source)- �� socket �xȡ��Ԫ�ؿ����÷ָ����з֡��Զ��x��source(Custom-source)
����ʹ��addSource��Kafka��(sh��)��(j��)����Flink����:
�����Ҫ�ⲿ��(sh��)��(j��)Դ����,��ʹ��addSource,�猢Kafka��(sh��)��(j��)����Flink,��������ه:
��Kafka��(sh��)��(j��)����Flink:
val properties = new Properties()
properties��setProperty("bootstrap��servers", "localhost:9092")
properties��setProperty("group��id", "consumer-group")
properties��setProperty("key��deserializer", "org��a(ch��n)pache��kafka��common��serialization��StringDeserializer")
properties��setProperty("value��deserializer", "org��a(ch��n)pache��kafka��common��serialization��StringDeserializer")
properties��setProperty("auto��offset��reset", "latest")
val source = env��a(ch��n)ddSource(new FlinkKafkaConsumer011[String]("sensor", new SimpleStringSchema(), properties))
���ھW(w��ng)�j(lu��)���ֵ�:
val source = env��socketTextStream("IP", PORT)
����Transform�D(zhu��n)�Q����1�� map
��DataSet�е�ÿһ��Ԫ���D(zhu��n)�Q������һ��Ԫ��
dataStream��map { x => x * 2 }
2�� FlatMap
����һ����(sh��)��(j��)Ԫ�������む,һ���������(sh��)��(j��)Ԫ�������ӷָ����~��flatmap����(sh��)
dataStream��flatMap { str => str��split(" ") }
3�� Filter
Ӌ(j��)��ÿ����(sh��)��(j��)Ԫ�IJ�������(sh��),�����溯��(sh��)����true�Ĕ�(sh��)��(j��)Ԫ���^�V����ֵ���^�V��
dataStream��filter { _ != 0 }
4�� KeyBy
߉�ό����օ^(q��)�鲻�ཻ�ķօ^(q��)��������ͬKeys������ӛ䛶�����oͬһ�օ^(q��)���ڃ�(n��i)��,keyBy()��ʹ��ɢ�зօ^(q��)��(sh��)�F(xi��n)�ġ�ָ���I�в�ͬ�ķ�����
���D(zhu��n)�Q����KeyedStream,���а���ʹ�ñ�Keys����B(t��i)�����KeyedStream��
dataStream��keyBy(0)
5�� Reduce
��Keys����(sh��)��(j��)���ϵġ��L�ӡ�Reduce������(d��ng)ǰ��(sh��)��(j��)Ԫ�c���һ��Reduce��ֵ�M�ϲ��l(f��)����ֵ
keyedStream��reduce { _ + _ }
6�� Fold
���г�ʼֵ�ı�Keys����(sh��)��(j��)���ϵġ��L�ӡ��ۯB������(d��ng)ǰ��(sh��)��(j��)Ԫ�c����ۯB��ֵ�M�ϲ��l(f��)����ֵ
val result: DataStream[String] = keyedStream��fold("start")((str, i) => { str + "-" + i })
// ���:��(d��ng)�������a��(y��ng)��������(1,2,3,4,5)�r(sh��),ݔ���Y(ji��)����start-1��,��start-1-2��,��start-1-2-3��,������
7�� Aggregations
�ڱ�Keys����(sh��)��(j��)���ϝL�Ӿۺϡ�min��minBy֮�g�IJ��min������Сֵ,��minBy����ԓ�ֶ��о�����Сֵ�Ĕ�(sh��)��(j��)Ԫ(max��maxBy��ͬ)��
keyedStream��sum(0);
keyedStream��min(0);
keyedStream��max(0);
keyedStream��minBy(0);
keyedStream��maxBy(0);
8�� Window
�������ѽ�(j��ng)�օ^(q��)��KeyedStream�϶��xWindows��Windows����(j��)ijЩ����(����,�����5���(n��i)���_(d��)�Ĕ�(sh��)��(j��))��ÿ��Keys�еĔ�(sh��)��(j��)�M(j��n)�зֽM���@�ﲻ�ٌ������M(j��n)��Ԕ��,���P(gu��n)���ڵ������f��,Ո�鿴�@ƪ����:Flink �ИO����Ҫ�� Time �c Window Ԕ��(x��)����
dataStream��keyBy(0)��window(TumblingEventTimeWindows��of(Time��seconds(5)));
9�� WindowAll
Windows�����ڳ�Ҏ(gu��)DataStream�϶��x��Windows����(j��)ijЩ����(����,�����5���(n��i)���_(d��)�Ĕ�(sh��)��(j��))���������¼��M(j��n)�зֽM��
ע��:���S����r��,�@�ǷDz����D(zhu��n)�Q������ӛ䛌��ռ���windowAll ���ӵ�һ���΄�(w��)�С�
dataStream��windowAll(TumblingEventTimeWindows��of(Time��seconds(5)))
10�� Window Apply
��һ�㺯��(sh��)��(y��ng)�����������ڡ�
ע��:���������ʹ��windowAll�D(zhu��n)�Q,�t��Ҫʹ��AllWindowFunction��
������һ���ք���ʹ��ڔ�(sh��)��(j��)Ԫ�ĺ���(sh��)
windowedStream��a(ch��n)pply { WindowFunction }
allWindowedStream��a(ch��n)pply { AllWindowFunction }
11�� Window Reduce
������(sh��)�s�p����(sh��)��(y��ng)���ڴ��ڲ����ؿsС��ֵ
windowedStream��reduce { _ + _ }
12�� Window Fold
������(sh��)�ۯB����(sh��)��(y��ng)���ڴ��ڲ������ۯBֵ
val result: DataStream[String] = windowedStream��fold("start", (str, i) => { str + "-" + i })
// �������a��(y��ng)��������(1,2,3,4,5)�r(sh��),�������ۯB���ַ�����start-1-2-3-4-5��
13�� Union
�ɂ��������(sh��)��(j��)����(li��n)��,��(chu��ng)���������������������Д�(sh��)��(j��)Ԫ��������ע��:�������(sh��)��(j��)���c����(li��n)��,�t���ڽY(ji��)�����Ы@ȡ�ɴΔ�(sh��)��(j��)Ԫ
dataStream��union(otherStream1, otherStream2, ������)
14�� Window Join
�ڽo��Keys�����������B�Ӄɂ���(sh��)��(j��)��
dataStream��join(otherStream)
��where(
�ڽo���ĕr(sh��)�g�g���(n��i)ʹ�ù���Keys�P(gu��n)(li��n)�ɂ���Key���Ĕ�(sh��)��(j��)���ăɂ���(sh��)��(j��)Ԫe1��e2,�Ա�e1��timestamp + lowerBound <= e2��timestamp <= e1��timestamp + upperBound
am��intervalJoin(otherKeyedStream)
��between(Time��milliseconds(-2), Time��milliseconds(2))
��upperBoundExclusive(true)
��lowerBoundExclusive(true)
��process(new IntervalJoinFunction() {������})
16�� Window CoGroup
�ڽo��Keys���������ό��ɂ���(sh��)��(j��)���M(j��n)��Cogroup
dataStream��coGroup(otherStream)
��where(0)��equalTo(1)
��window(TumblingEventTimeWindows��of(Time��seconds(3)))
��a(ch��n)pply (new CoGroupFunction () {������})
17�� Connect
���B�ӡ��ɂ���������͵Ĕ�(sh��)��(j��)�����B�����S�ɂ���֮�g�Ĺ�����B(t��i)
DataStream
������B�Ӕ�(sh��)��(j��)���ϵ�map��flatMap
connectedStreams��map(
(_ : Int) => true,
(_ : String) => false)connectedStreams��flatMap(
(_ : Int) => true,
(_ : String) => false)
19�� Split
����(j��)ijЩ��(bi��o)��(zh��n)������֞�ɂ����������
val split = someDataStream��split(
(num: Int) =>
(num % 2) match {
case 0 => List("even")
case 1 => List("odd")
})
20�� Select
�IJ�������x��һ���������
SplitStream
֧����(sh��)��(j��)ݔ����:
�����ļ�(������̎��)���ؼ���(������̎��)HDFS(������̎��)
����֮��,߀֧��:
sink��kafkasink��mysqlsink��redis
������sink��kafka����:
val sinkTopic = "test"
//�����
case class Student(id: Int, name: String, addr: String, sex: String)
val mapper: ObjectMapper = new ObjectMapper()
//�������D(zhu��n)�Q���ַ���
def toJsonString(T: Object): String = {
mapper��registerModule(DefaultScalaModule)
mapper��writeValueAsString(T)
}
def main(args: Array[String]): Unit = {
//1����(chu��ng)������(zh��)�Эh(hu��n)��
val env = StreamExecutionEnvironment��getExecutionEnvironment
//2����(zh��n)�䔵(sh��)��(j��)
val dataStream: DataStream[Student] = env��fromElements(
Student(8, "xiaoming", "beijing biejing", "female")
)
//��student�D(zhu��n)�Q���ַ���
val studentStream: DataStream[String] = dataStream��map(student =>
toJsonString(student) // �@����Ҫ�@ʾSerializerFeature�е�ijһ��,��t����(b��o)ͬ�r(sh��)ƥ��ɂ��������e�`
)
//studentStream��print()
val prop = new Properties()
prop��setProperty("bootstrap��servers", "node01:9092")
val myProducer = new FlinkKafkaProducer011[String](sinkTopic, new KeyedSerializationSchemaWrapper[String](new SimpleStringSchema()), prop)
studentStream��a(ch��n)ddSink(myProducer)
studentStream��print()
env��execute("Flink add sink")
}
�塢��̎���е�Time�cWindow
Flink ����ʽ�ġ���(sh��)�r(sh��)�� Ӌ(j��)�����档
����һ��Ԓ���Ѓɂ�����,һ������ʽ,һ���nj�(sh��)�r(sh��)��
��ʽ:���ǔ�(sh��)��(j��)ԴԴ��������M(j��n)��,Ҳ���ǔ�(sh��)��(j��)�]��߅��,�����҂�Ӌ(j��)��ĕr(sh��)������һ����߅��ķ�����(n��i)�M(j��n)��,�����@�������һ�����},߅����ô�_��?�o�Ǿ̓ɷN��ʽ,����(j��)�r(sh��)�g�λ��ߔ�(sh��)��(j��)���M(j��n)�д_��,����(j��)�r(sh��)�g�ξ���ÿ�����L�r(sh��)�g�̈́���һ��߅��,����(j��)��(sh��)��(j��)������ÿ�����ٗl��(sh��)��(j��)����һ��߅��,Flink �о����@ô����߅���,���ĕ�Ԕ��(x��)�v�⡣
��(sh��)�r(sh��):���ǔ�(sh��)��(j��)�l(f��)���^��֮�����R���M(j��n)�����P(gu��n)��Ӌ(j��)��,Ȼ�Y(ji��)��ݔ�����@���Ӌ(j��)���ЃɷN:
һ�N��ֻ��߅���(n��i)�Ĕ�(sh��)��(j��)�M(j��n)��Ӌ(j��)��,�@�N������,����y(t��ng)Ӌ(j��)ÿ���Ñ�������犃�(n��i)�g�[������(sh��)��,�Ϳ���ȡ������犃�(n��i)�����Д�(sh��)��(j��),Ȼ�����(j��)ÿ���Ñ��ֽM,�y(t��ng)Ӌ(j��)���Ŀ���(sh��)��
��һ�N��߅���(n��i)��(sh��)��(j��)�c�ⲿ��(sh��)��(j��)�M(j��n)���P(gu��n)(li��n)Ӌ(j��)��,����:�y(t��ng)Ӌ(j��)������犃�(n��i)�g�[�����Ñ����ǁ�����Щ�^(q��),�@�N����Ҫ�����犃�(n��i)�g�[�����Ñ���Ϣ�c hive �еĵ^(q��)�S���M(j��n)���P(gu��n)(li��n),Ȼ�����M(j��n)�����P(gu��n)Ӌ(j��)�㡣
����(ji��)���v�� Flink ��(n��i)�ݾ��LJ��@���ϸ����M(j��n)��Ԕ��(x��)������!
1�� Time
��Flink��,����ԕr(sh��)�g�΄���߅���Ԓ,��ô�r(sh��)�g����һ���O����Ҫ���ֶΡ�
Flink�еĕr(sh��)�g�����N���,���D��ʾ:
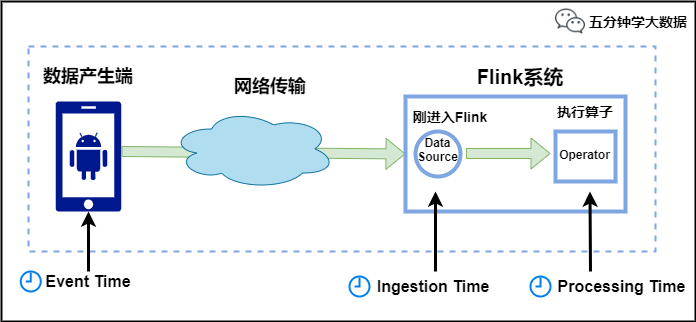
Event Time:���¼���(chu��ng)���ĕr(sh��)�g����ͨ�����¼��еĕr(sh��)�g������,����ɼ�����־��(sh��)��(j��)��,ÿһ�l��־����ӛ��Լ������ɕr(sh��)�g,Flinkͨ�^�r(sh��)�g���������L���¼��r(sh��)�g����
Ingestion Time:�ǔ�(sh��)��(j��)�M(j��n)��Flink�ĕr(sh��)�g��
Processing Time:��ÿһ����(zh��)�л��ڕr(sh��)�g���������ӵı���ϵ�y(t��ng)�r(sh��)�g,�c�C(j��)�����P(gu��n),Ĭ�J(r��n)�ĕr(sh��)�g���Ծ���Processing Time��
����,һ�l��־�M(j��n)��Flink�ĕr(sh��)�g��2021-01-22 10:00:00��123,���_(d��)Window��ϵ�y(t��ng)�r(sh��)�g��2021-01-22 10:00:01��234,��־�ă�(n��i)������:
2021-01-06 18:37:15��624 INFO Fail over to rm2
���ژI(y��)��(w��)���f,Ҫ�y(t��ng)Ӌ(j��)1min��(n��i)�Ĺ�����־����(sh��),�Ă��r(sh��)�g���������x��?���� eventTime,��?y��n)��҂�Ҫ���?j��)��־�����ɕr(sh��)�g�M(j��n)�нy(t��ng)Ӌ(j��)��
2�� Window
Window,������,�҂�ǰ��һֱ�ᵽ��߅������@���Window(����)��
�ٷ����:��ʽӋ(j��)����һ�N���O(sh��)Ӌ(j��)����̎��o�ޔ�(sh��)��(j��)���Ĕ�(sh��)��(j��)̎������,���o�ޔ�(sh��)��(j��)����ָһ�N�������L�ı��|(zh��)�ϟo�Ĕ�(sh��)��(j��)��,��window��һ�N�и�o�ޔ�(sh��)��(j��)�����މK�M(j��n)��̎�����ֶΡ�
����Window�ǟo�ޔ�(sh��)��(j��)��̎���ĺ���,Window��һ���o��stream��ֳ�����С�ġ�buckets��Ͱ,�҂��������@ЩͰ����Ӌ(j��)�������
Window���
���Ą��_ʼ�ᵽ,���ִ��ھ̓ɷN��ʽ:
����(j��)�r(sh��)�g�M(j��n)�н�ȡ(time-driven-window),����ÿ1��犽y(t��ng)Ӌ(j��)һ�λ�ÿ10��犽y(t��ng)Ӌ(j��)һ�Ρ�����(j��)��(sh��)��(j��)�M(j��n)�н�ȡ(data-driven-window),����ÿ5����(sh��)��(j��)�y(t��ng)Ӌ(j��)һ�λ�ÿ50����(sh��)��(j��)�y(t��ng)Ӌ(j��)һ�Ρ�
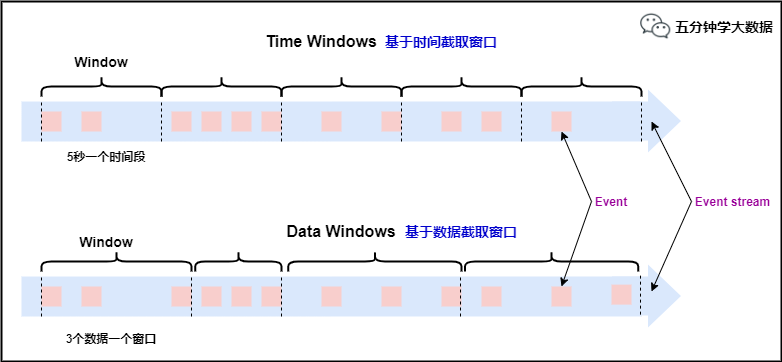
�������
����TimeWindow(����(j��)�r(sh��)�g���ִ���), ���Ը���(j��)���ڌ�(sh��)�F(xi��n)ԭ���IJ�ͬ�ֳ����:�L�Ӵ���(Tumbling Window)�����Ӵ���(Sliding Window)�͕�Ԓ����(Session Window)��
�L�Ӵ���(Tumbling Windows)
����(sh��)��(j��)����(j��)�̶��Ĵ����L�Ȍ���(sh��)��(j��)�M(j��n)����Ƭ��
���c(di��n):�r(sh��)�g���R,�����L�ȹ̶�,�]���دB��
�L�Ӵ��ڷ�������ÿ��Ԫ�ط��䵽һ��ָ�����ڴ�С�Ĵ�����,�L�Ӵ�����һ���̶��Ĵ�С,���Ҳ������F(xi��n)�دB��
����:�����ָ����һ��5��犴�С�ĝL�Ӵ���,���ڵĄ�(chu��ng)�����D��ʾ:

�L�Ӵ���
�m�È���:�m����BI�y(t��ng)Ӌ(j��)��(��ÿ���r(sh��)�g�εľۺ�Ӌ(j��)��)��
���Ӵ���(Sliding Windows)
���Ӵ����ǹ̶����ڵĸ��V�x��һ�N��ʽ,���Ӵ����ɹ̶��Ĵ����L�Ⱥͻ����g���M�ɡ�
���c(di��n):�r(sh��)�g���R,�����L�ȹ̶�,���دB��
���Ӵ��ڷ�������Ԫ�ط��䵽�̶��L�ȵĴ�����,�c�L�Ӵ������,���ڵĴ�С�ɴ��ڴ�С����(sh��)������,��һ�����ڻ��Ӆ���(sh��)���ƻ��Ӵ����_ʼ���l�ʡ����,���Ӵ���������Ӆ���(sh��)С�ڴ��ڴ�С��Ԓ,�����ǿ����دB��,���@�N��r��Ԫ�ؕ������䵽���������С�
����,����10��犵Ĵ��ں�5��犵Ļ���,��ôÿ��������5��犵Ĵ�����������ς�10��犮a(ch��n)���Ĕ�(sh��)��(j��),���D��ʾ:
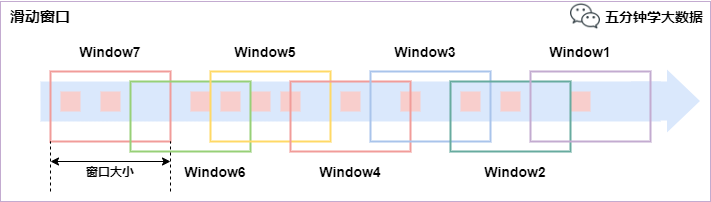
���Ӵ���
�m�È���:�����һ���r(sh��)�g��(n��i)�Ľy(t��ng)Ӌ(j��)(��ij�ӿ����5min��ʧ���ʁ�Q���Ƿ�Ҫ��(b��o)��)��
��Ԓ����(Session Windows)
��һϵ���¼��M��һ��ָ���r(sh��)�g�L�ȵ�timeout�g϶�M��,�����web��(y��ng)�õ�session,Ҳ����һ�Εr(sh��)�g�]�н��յ���(sh��)��(j��)�͕������µĴ��ڡ�
���c(di��n):�r(sh��)�g�o���R��
session���ڷ�����ͨ�^session��Ӂ팦Ԫ���M(j��n)�зֽM,session���ڸ��L�Ӵ��ںͻ��Ӵ������,�������دB�̶����_ʼ�r(sh��)�g�ͽY(ji��)���r(sh��)�g����r,�෴,��(d��ng)����һ���̶��ĕr(sh��)�g���ڃ�(n��i)�����յ�Ԫ��,���ǻ���g���a(ch��n)��,�ǂ��@�����ھ͕��P(gu��n)�]��һ��session����ͨ�^һ��session�g�������,�@��session�g�����x�˷ǻ��S���ڵ��L��,��(d��ng)�@���ǻ��S���ڮa(ch��n)��,��ô��(d��ng)ǰ��session���P(gu��n)�]���Һ��m(x��)��Ԫ�،������䵽�µ�session������ȥ��
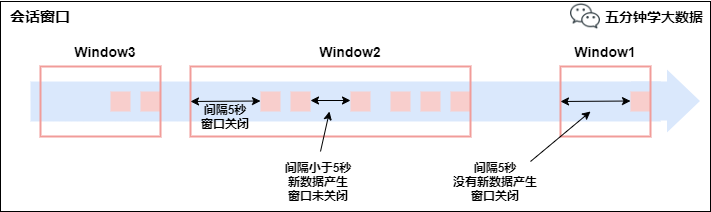
��Ԓ����3�� Window API1) TimeWindow
TimeWindow�nj�ָ���r(sh��)�g������(n��i)�����Д�(sh��)��(j��)�M��һ��window,һ�Ό�һ��window��������Д�(sh��)��(j��)�M(j��n)��Ӌ(j��)��(���DZ����_�^�f�Č�һ��߅���(n��i)�Ĕ�(sh��)��(j��)�M(j��n)��Ӌ(j��)��)��
�҂��� �t�G��·��ͨ�^����܇��(sh��)�� ������:
�t�G��·�ڕ�����܇ͨ�^,һ�����ж�����܇ͨ�^,�o��Ӌ(j��)�㡣��?y��n)�܇��ԴԴ���?Ӌ(j��)��]��߅�硣
�����҂��y(t��ng)Ӌ(j��)ÿ15���ͨ�^�t·������܇��(sh��)��,���һ��15���2�v,�ڶ���15���3�v,������15���1�v ������
tumbling-time-window (�o�دB��(sh��)��(j��))
�҂�ʹ�� Linux �е� nc ����ģ�M��(sh��)��(j��)�İl(f��)�ͷ�
1���_���l(f��)�Ͷ˿�,�˿�̖��9999
nc -lk 9999
2���l(f��)�̓�(n��i)��(key ������ͬ��·��,value ����ÿ��ͨ�^��܇�v)
һ�ΰl(f��)��һ��,�l(f��)�͵ĕr(sh��)�g�g��������܇��(j��ng)�^�ĕr(sh��)�g�g��
9,3
9,2
9,7
4,9
2,6
1,5
2,3
5,7
5,4
Flink �M(j��n)�вɼ���(sh��)��(j��)��Ӌ(j��)��:
object Window {
def main(args: Array[String]): Unit = {
//TODO time-window
//1����(chu��ng)���\(y��n)�Эh(hu��n)��
val env = StreamExecutionEnvironment��getExecutionEnvironment
//2�����x��(sh��)��(j��)����Դ
val text = env��socketTextStream("localhost", 9999)
//3���D(zhu��n)�Q��(sh��)��(j��)��ʽ,text->CarWc
case class CarWc(sensorId: Int, carCnt: Int)
val ds1: DataStream[CarWc] = text��map {
line => {
val tokens = line��split(",")
CarWc(tokens(0)��trim��toInt, tokens(1)��trim��toInt)
}
}
//4����(zh��)�нy(t��ng)Ӌ(j��)����,ÿ��sensorIdһ��tumbling����,���ڵĴ�С��5��
//Ҳ�����f,ÿ5��犽y(t��ng)Ӌ(j��)һ��,���@�^ȥ��5��犃�(n��i),����·��ͨ�^�t�G����܇�Ĕ�(sh��)����
val ds2: DataStream[CarWc] = ds1
��keyBy("sensorId")
��timeWindow(Time��seconds(5))
��sum("carCnt")
//5���@ʾ�y(t��ng)Ӌ(j��)�Y(ji��)��
ds2��print()
//6���|�l(f��)��Ӌ(j��)��
env��execute(this��getClass��getName)
}
}
�҂��l(f��)�͵Ĕ�(sh��)��(j��)���]��ָ���r(sh��)�g�ֶ�,����Flinkʹ�õ���Ĭ�J(r��n)�� Processing Time,Ҳ����Flinkϵ�y(t��ng)̎�픵(sh��)��(j��)�r(sh��)�ĕr(sh��)�g��
sliding-time-window (���دB��(sh��)��(j��))//1����(chu��ng)���\(y��n)�Эh(hu��n)��
val env = StreamExecutionEnvironment��getExecutionEnvironment
//2�����x��(sh��)��(j��)����Դ
val text = env��socketTextStream("localhost", 9999)
//3���D(zhu��n)�Q��(sh��)��(j��)��ʽ,text->CarWc
case class CarWc(sensorId: Int, carCnt: Int)
val ds1: DataStream[CarWc] = text��map {
line => {
val tokens = line��split(",")
CarWc(tokens(0)��trim��toInt, tokens(1)��trim��toInt)
}
}
//4����(zh��)�нy(t��ng)Ӌ(j��)����,ÿ��sensorIdһ��sliding����,���ڕr(sh��)�g10��,���ӕr(sh��)�g5��
//Ҳ�����f,ÿ5��犽y(t��ng)Ӌ(j��)һ��,���@�^ȥ��10��犃�(n��i),����·��ͨ�^�t�G����܇�Ĕ�(sh��)����
val ds2: DataStream[CarWc] = ds1
��keyBy("sensorId")
��timeWindow(Time��seconds(10), Time��seconds(5))
��sum("carCnt")
//5���@ʾ�y(t��ng)Ӌ(j��)�Y(ji��)��
ds2��print()
//6���|�l(f��)��Ӌ(j��)��
env��execute(this��getClass��getName)
2) CountWindow
CountWindow����(j��)��������ͬkeyԪ�صĔ�(sh��)�����|�l(f��)��(zh��)��,��(zh��)�Еr(sh��)ֻӋ(j��)��Ԫ��?c��i)?sh��)���_(d��)�����ڴ�С��key����(y��ng)�ĽY(ji��)����
ע��:CountWindow��window_sizeָ������ͬKey��Ԫ�صĂ���(sh��),����ݔ�������Ԫ�صĿ���(sh��)��
tumbling-count-window (�o�دB��(sh��)��(j��))//1����(chu��ng)���\(y��n)�Эh(hu��n)��
val env = StreamExecutionEnvironment��getExecutionEnvironment
//2�����x��(sh��)��(j��)����Դ
val text = env��socketTextStream("localhost", 9999)
//3���D(zhu��n)�Q��(sh��)��(j��)��ʽ,text->CarWc
case class CarWc(sensorId: Int, carCnt: Int)
val ds1: DataStream[CarWc] = text��map {
(f) => {
val tokens = f��split(",")
CarWc(tokens(0)��trim��toInt, tokens(1)��trim��toInt)
}
}
//4����(zh��)�нy(t��ng)Ӌ(j��)����,ÿ��sensorIdһ��tumbling����,���ڵĴ�С��5
//����key�M(j��n)���ռ�,����(y��ng)��key���F(xi��n)�ĴΔ�(sh��)�_(d��)��5������һ���Y(ji��)��
val ds2: DataStream[CarWc] = ds1
��keyBy("sensorId")
��countWindow(5)
��sum("carCnt")
//5���@ʾ�y(t��ng)Ӌ(j��)�Y(ji��)��
ds2��print()
//6���|�l(f��)��Ӌ(j��)��
env��execute(this��getClass��getName)
sliding-count-window (���دB��(sh��)��(j��))
ͬ��Ҳ�Ǵ����L�Ⱥͻ��Ӵ��ڵIJ���:�����L����5,�����L����3
//1����(chu��ng)���\(y��n)�Эh(hu��n)��
val env = StreamExecutionEnvironment��getExecutionEnvironment
//2�����x��(sh��)��(j��)����Դ
val text = env��socketTextStream("localhost", 9999)
//3���D(zhu��n)�Q��(sh��)��(j��)��ʽ,text->CarWc
case class CarWc(sensorId: Int, carCnt: Int)
val ds1: DataStream[CarWc] = text��map {
(f) => {
val tokens = f��split(",")
CarWc(tokens(0)��trim��toInt, tokens(1)��trim��toInt)
}
}
//4����(zh��)�нy(t��ng)Ӌ(j��)����,ÿ��sensorIdһ��sliding����,���ڴ�С3�l��(sh��)��(j��),���ڻ��Ӟ�3�l��(sh��)��(j��)
//Ҳ�����f,ÿ��·�ڷքe�y(t��ng)Ӌ(j��),�յ��P(gu��n)������3�l��Ϣ�r(sh��)�y(t��ng)Ӌ(j��)�����5�l��Ϣ��,����·��ͨ�^����܇��(sh��)��
val ds2: DataStream[CarWc] = ds1
��keyBy("sensorId")
��countWindow(5, 3)
��sum("carCnt")
//5���@ʾ�y(t��ng)Ӌ(j��)�Y(ji��)��
ds2��print()
//6���|�l(f��)��Ӌ(j��)��
env��execute(this��getClass��getName)
Window ���Y(ji��)
flink֧�փɷN���ִ��ڵķ�ʽ(time��count)
�������(j��)�r(sh��)�g���ִ���,��ô������һ��time-window
�������(j��)��(sh��)��(j��)���ִ���,��ô������һ��count-window
flink֧�ִ��ڵăɂ���Ҫ����(size��interval)
���size=interval,��ô�͕��γ�tumbling-window(�o�دB��(sh��)��(j��))
���size>interval,��ô�͕��γ�sliding-window(���دB��(sh��)��(j��))
���size
ͨ�^�M�Ͽ��Եó��ķN��������
time-tumbling-window �o�دB��(sh��)��(j��)�ĕr(sh��)�g����,�O(sh��)�÷�ʽ�e��:timeWindow(Time��seconds(5))
time-sliding-window ���دB��(sh��)��(j��)�ĕr(sh��)�g����,�O(sh��)�÷�ʽ�e��:timeWindow(Time��seconds(5), Time��seconds(3))
count-tumbling-window�o�دB��(sh��)��(j��)�Ĕ�(sh��)������,�O(sh��)�÷�ʽ�e��:countWindow(5)
count-sliding-window ���دB��(sh��)��(j��)�Ĕ�(sh��)������,�O(sh��)�÷�ʽ�e��:countWindow(5,3)
3) Window Reduce
WindowedStream �� DataStream:�owindow�xһ��reduce���ܵĺ���(sh��),������һ���ۺϵĽY(ji��)����
import org��a(ch��n)pache��flink��streaming��a(ch��n)pi��scala��StreamExecutionEnvironment
import org��a(ch��n)pache��flink��a(ch��n)pi��scala��_
import org��a(ch��n)pache��flink��streaming��a(ch��n)pi��windowing��time��Time
object StreamWindowReduce {
def main(args: Array[String]): Unit = {
// �@ȡ��(zh��)�Эh(hu��n)��
val env = StreamExecutionEnvironment��getExecutionEnvironment
// ��(chu��ng)��SocketSource
val stream = env��socketTextStream("node01", 9999)
// ��stream�M(j��n)��̎������key�ۺ�
val streamKeyBy = stream��map(item => (item, 1))��keyBy(0)
// ����r(sh��)�g����
val streamWindow = streamKeyBy��timeWindow(Time��seconds(5))
// ��(zh��)�оۺϲ���
val streamReduce = streamWindow��reduce(
(item1, item2) => (item1��_1, item1��_2 + item2��_2)
)
// ���ۺϔ�(sh��)��(j��)�����ļ�
streamReduce��print()
// ��(zh��)���
env��execute("TumblingWindow")
}
}
4) Window Apply
apply���������M(j��n)��һЩ�Զ��x̎��,ͨ�^������(n��i)��ķ����팍(sh��)�F(xi��n)����(d��ng)��һЩ��(f��)�sӋ(j��)��r(sh��)ʹ�á�
�÷�
��(sh��)�F(xi��n)һ�� WindowFunction �ָ��ԓķ��͞� [ݔ�딵(sh��)��(j��)���, ݔ����(sh��)��(j��)���, keyBy��ʹ�÷ֽM�ֶε����, �������]
ʾ��:ʹ��apply�����팍(sh��)�F(xi��n)���~�y(t��ng)Ӌ(j��)
���E:
�@ȡ��̎���\(y��n)�Эh(hu��n)����(g��u)��socket����(sh��)��(j��)Դ,��ָ��IP��ַ�Ͷ˿�̖�����յ��Ĕ�(sh��)��(j��)�D(zhu��n)�Q�Ɇ��~Ԫ�Mʹ�� keyBy �M(j��n)�з���(�ֽM)ʹ�� timeWinodw ָ�����ڵ��L��(ÿ3��Ӌ(j��)��һ��)��(sh��)�F(xi��n)һ��WindowFunction������(n��i)���apply�����Ќ�(sh��)�F(xi��n)�ۺ�Ӌ(j��)��ʹ��Collector��collect�ռ���(sh��)��(j��)
���Ĵ��a����:
//1�� �@ȡ��̎���\(y��n)�Эh(hu��n)��
val env = StreamExecutionEnvironment��getExecutionEnvironment
//2�� ��(g��u)��socket����(sh��)��(j��)Դ,��ָ��IP��ַ�Ͷ˿�̖
val textDataStream = env��socketTextStream("node01", 9999)��flatMap(_��split(" "))
//3�� �����յ��Ĕ�(sh��)��(j��)�D(zhu��n)�Q�Ɇ��~Ԫ�M
val wordDataStream = textDataStream��map(_->1)
//4�� ʹ�� keyBy �M(j��n)�з���(�ֽM)
val groupedDataStream: KeyedStream[(String, Int), String] = wordDataStream��keyBy(_��_1)
//5�� ʹ�� timeWinodw ָ�����ڵ��L��(ÿ3��Ӌ(j��)��һ��)
val windowDataStream: WindowedStream[(String, Int), String, TimeWindow] = groupedDataStream��timeWindow(Time��seconds(3))
//6�� ��(sh��)�F(xi��n)һ��WindowFunction������(n��i)���
val reduceDatStream: DataStream[(String, Int)] = windowDataStream��a(ch��n)pply(new RichWindowFunction[(String, Int), (String, Int), String, TimeWindow] {
//��apply�����Ќ�(sh��)�F(xi��n)��(sh��)��(j��)�ľۺ�
override def apply(key: String, window: TimeWindow, input: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
println("hello world")
val tuple = input��reduce((t1, t2) => {
(t1��_1, t1��_2 + t2��_2)
})
//��Ҫ���صĔ�(sh��)��(j��)�ռ�����,�l(f��)�ͻ�ȥ
out��collect(tuple)
}
})
reduceDatStream��print()
env��execute()
5) Window Fold
WindowedStream �� DataStream:�o�����xһ��fold���ܵĺ���(sh��),������һ��fold��ĽY(ji��)����
import org��a(ch��n)pache��flink��streaming��a(ch��n)pi��scala��StreamExecutionEnvironment
import org��a(ch��n)pache��flink��a(ch��n)pi��scala��_
import org��a(ch��n)pache��flink��streaming��a(ch��n)pi��windowing��time��Time
object StreamWindowFold {
def main(args: Array[String]): Unit = {
// �@ȡ��(zh��)�Эh(hu��n)��
val env = StreamExecutionEnvironment��getExecutionEnvironment
// ��(chu��ng)��SocketSource
val stream = env��socketTextStream("node01", 9999,'',3)
// ��stream�M(j��n)��̎������key�ۺ�
val streamKeyBy = stream��map(item => (item, 1))��keyBy(0)
// ����L�Ӵ���
val streamWindow = streamKeyBy��timeWindow(Time��seconds(5))
// ��(zh��)��fold����
val streamFold = streamWindow��fold(100){
(begin, item) =>
begin + item��_2
}
// ���ۺϔ�(sh��)��(j��)�����ļ�
streamFold��print()
// ��(zh��)���
env��execute("TumblingWindow")
}
}
6) Aggregation on Window
WindowedStream �� DataStream:��һ��window��(n��i)������Ԫ�����ۺϲ�����min�� minBy�ą^(q��)�e��min���ص�����Сֵ,��minBy���ص��ǰ�����Сֵ�ֶε�Ԫ��(ͬ�ӵ�ԭ���m���� max �� maxBy)��
import org��a(ch��n)pache��flink��streaming��a(ch��n)pi��scala��StreamExecutionEnvironment
import org��a(ch��n)pache��flink��streaming��a(ch��n)pi��windowing��time��Time
import org��a(ch��n)pache��flink��a(ch��n)pi��scala��_
object StreamWindowAggregation {
def main(args: Array[String]): Unit = {
// �@ȡ��(zh��)�Эh(hu��n)��
val env = StreamExecutionEnvironment��getExecutionEnvironment
// ��(chu��ng)��SocketSource
val stream = env��socketTextStream("node01", 9999)
// ��stream�M(j��n)��̎������key�ۺ�
val streamKeyBy = stream��map(item => (item��split(" ")(0), item��split(" ")(1)))��keyBy(0)
// ����L�Ӵ���
val streamWindow = streamKeyBy��timeWindow(Time��seconds(5))
// ��(zh��)�оۺϲ���
val streamMax = streamWindow��max(1)
// ���ۺϔ�(sh��)��(j��)�����ļ�
streamMax��print()
// ��(zh��)���
env��execute("TumblingWindow")
}
}
4�� EventTime�cWindow1) EventTime�������c�F(xi��n)��(sh��)�����еĕr(sh��)�g�Dz�һ�µ�,��flink�б����֞��¼��r(sh��)�g,��ȡ�r(sh��)�g,̎��r(sh��)�g���N�������EventTime�����(zh��n)�����x�r(sh��)�g�����nj��γ�EventTimeWindow,Ҫ����Ϣ�����͑�(y��ng)ԓ�y��EventTime�����IngesingtTime�����(zh��n)�����x�r(sh��)�g�����nj��γ�IngestingTimeWindow,��source��systemTime���(zh��n)�������ProcessingTime����(zh��n)�����x�r(sh��)�g�����nj��γ�ProcessingTimeWindow,��operator��systemTime���(zh��n)��
��Flink����ʽ̎����,�^�ֵĘI(y��)��(w��)����ʹ��eventTime,һ��ֻ��eventTime�o��ʹ�Õr(sh��),�ŕ�����ʹ��ProcessingTime����IngestionTime��
���Ҫʹ��EventTime,��ô��Ҫ����EventTime�ĕr(sh��)�g����,���뷽ʽ������ʾ:
val env = StreamExecutionEnvironment��getExecutionEnvironment
// ���{(di��o)�Õr(sh��)���_ʼ�oenv��(chu��ng)����ÿһ��stream�ӕr(sh��)�g����
env��setStreamTimeCharacteristic(TimeCharacteristic��EventTime)
2) Watermark
�҂�֪��,��̎����¼��a(ch��n)��,������(j��ng) source,�ٵ� operator,���g����һ���^�̺͕r(sh��)�g��,�mȻ����r��,���� operator �Ĕ�(sh��)��(j��)���ǰ����¼��a(ch��n)���ĕr(sh��)�g������,����Ҳ���ų����ھW(w��ng)�j(lu��)��������ԭ��,��(d��o)�y��Įa(ch��n)��,���^�y��,����ָ Flink ���յ����¼����Ⱥ�����LJ�(y��n)�����¼��� Event Time ������е�,���� Flink ����O(sh��)Ӌ(j��)�ĕr(sh��)��,�Ϳ��]���˾W(w��ng)�j(lu��)���t,�W(w��ng)�j(lu��)�y��Ȇ��},���������һ���������:ˮӡ(WaterMark);
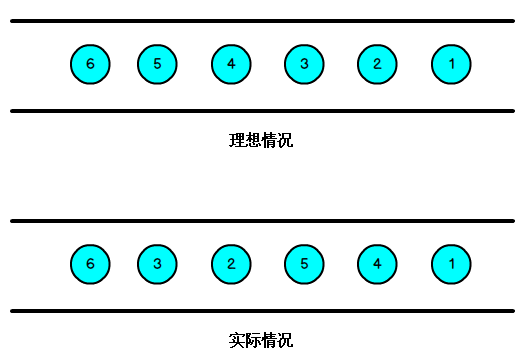
���ψD��ʾ,�ͳ��F(xi��n)һ�����},һ�����F(xi��n)�y��,���ֻ����(j��) EventTime �Q�� Window ���\(y��n)��,�҂��������_��(sh��)��(j��)�Ƿ�ȫ����λ,���ֲ��ܟo���ڵĵ���ȥ,�˕r(sh��)���Ҫ�Ђ��C(j��)�Ɓ����Cһ���ض��ĕr(sh��)�g��,����|�l(f��) Window ȥ�M(j��n)��Ӌ(j��)����,�@���e�ęC(j��)��,���� Watermark��
Watermark ������̎��y���¼���,�����_��̎��y���¼�,ͨ���� Watermark �C(j��)�ƽY(ji��)�� Window �팍(sh��)�F(xi��n)��
��(sh��)��(j��)���е� Watermark ���ڱ�ʾ timestamp С�� Watermark �Ĕ�(sh��)��(j��),���ѽ�(j��ng)���_(d��)��,���,Window �Ĉ�(zh��)��Ҳ���� Watermark �|�l(f��)�ġ�
Watermark ���������һ�����t�|�l(f��)�C(j��)��,�҂������O(sh��)�� Watermark ���ӕr(sh��)�r(sh��)�L t,ÿ��ϵ�y(t��ng)��У�(y��n)�ѽ�(j��ng)���_(d��)�Ĕ�(sh��)��(j��)������ maxEventTime,Ȼ���J(r��n)�� EventTime С�� maxEventTime - t �����Д�(sh��)��(j��)���ѽ�(j��ng)���_(d��),����д��ڵ�ֹͣ�r(sh��)�g���� maxEventTime �C t,��ô�@�����ڱ��|�l(f��)��(zh��)�С�
��������Watermarker���D��ʾ:(Watermark�O(sh��)�Þ�0)

����(sh��)��(j��)��Watermark
�y������Watermarker���D��ʾ:(Watermark�O(sh��)�Þ�2)

�o��(sh��)��(j��)��Watermark
��(d��ng) Flink ���յ�ÿһ�l��(sh��)��(j��)�r(sh��),�����a(ch��n)��һ�l Watermark,�@�l Watermark �͵��ڮ�(d��ng)ǰ���е��_(d��)��(sh��)��(j��)�е� maxEventTime - ���t�r(sh��)�L,Ҳ�����f,Watermark ���ɔ�(sh��)��(j��)�y����,һ����(sh��)��(j��)�y���� Watermark �Ȯ�(d��ng)ǰδ�|�l(f��)�Ĵ��ڵ�ֹͣ�r(sh��)�gҪ��,��ô�͕��|�l(f��)����(y��ng)���ڵĈ�(zh��)�С����� Watermark ���ɔ�(sh��)��(j��)�y����,���,����\(y��n)���^���Пo���@ȡ�µĔ�(sh��)��(j��),��ô�]�б��|�l(f��)�Ĵ��ڌ����h(yu��n)�������|�l(f��)��
�ψD��,�҂��O(sh��)�õ����S������t���_(d��)�r(sh��)�g��2s,���ԕr(sh��)�g����7s���¼�����(y��ng)��Watermark��5s,�r(sh��)�g����12s���¼���Watermark��10s,����҂��Ĵ���1��1s��5s,����2��6s��10s,��ô�r(sh��)�g����7s���¼����_(d��)�r(sh��)��Watermarkerǡ���|�l(f��)����1,�r(sh��)�g����12s���¼����_(d��)�r(sh��)��Watermarkǡ���|�l(f��)����2��
3) Flink�����t����(sh��)��(j��)��̎��
waterMark��Window�C(j��)�ƽ�Q����ʽ��(sh��)��(j��)�āy���},������?y��n)����t��������`�Ĕ�(sh��)��(j��),���Ը���(j��)eventTime�M(j��n)�ИI(y��)��(w��)̎��,�����t�Ĕ�(sh��)��(j��)FlinkҲ���Լ��Ľ�Q�k��,��Ҫ���k���ǽo��һ�����S���t�ĕr(sh��)�g,��ԓ�r(sh��)�g������(n��i)�Կ��Խ���̎�����t��(sh��)��(j��)��
�O(sh��)�����S���t�ĕr(sh��)�g��ͨ�^ allowedLateness(lateness: Time) �O(sh��)��
�������t��(sh��)��(j��)�t��ͨ�^ sideOutputLateData(outputTag: OutputTag[T]) ����
�@ȡ���t��(sh��)��(j��)��ͨ�^ DataStream��getSideOutput(tag: OutputTag[X]) �@ȡ
���w���÷�����:
allowedLateness(lateness: Time)
def allowedLateness(lateness: Time): WindowedStream[T, K, W] = {
javaStream��a(ch��n)llowedLateness(lateness)
this
}
ԓ��������һ��Timeֵ,�O(sh��)�����S��(sh��)��(j��)�t���ĕr(sh��)�g,�@���r(sh��)�g�� WaterMark �еĕr(sh��)�g���ͬ���ف����һ��:
WaterMark=��(sh��)��(j��)���¼��r(sh��)�g-���S�y��r(sh��)�gֵ
�S����(sh��)��(j��)�ĵ���,waterMark��ֵ����������(sh��)��(j��)�¼��r(sh��)�g-���S�y��r(sh��)�gֵ,��������@�r(sh��)�����һ�l�vʷ��(sh��)��(j��),waterMarkֵ�t�������¡����ā��f,waterMark�Ǟ����ܽ��յ��M���ܶ�āy��(sh��)��(j��)��
���@���Timeֵ,��Ҫ�Ǟ��˵ȴ��t���Ĕ�(sh��)��(j��),��һ���r(sh��)�g������(n��i),�������ԓ���ڵĔ�(sh��)��(j��)����,�ԕ��M(j��n)��Ӌ(j��)��,�������Ӌ(j��)�㷽ʽ�м�(x��)�f��
ע��:ԓ����ֻᘌ��ڻ���event-time�Ĵ���,����ǻ���processing-time,����ָ���˷����timeֵ�t������������
sideOutputLateData(outputTag: OutputTag[T])
def sideOutputLateData(outputTag: OutputTag[T]): WindowedStream[T, K, W] = {
javaStream��sideOutputLateData(outputTag)
this
}
ԓ�����nj��t���Ĕ�(sh��)��(j��)�������o����outputTag����(sh��),��OutputTag�t���Á��(bi��o)ӛ���t��(sh��)��(j��)��һ������
DataStream��getSideOutput(tag: OutputTag[X])
ͨ�^window�Ȳ������ص�DataStream�{(di��o)��ԓ����,�����(bi��o)ӛ���t��(sh��)��(j��)�Č�����@ȡ���t�Ĕ�(sh��)��(j��)��
�����t��(sh��)��(j��)������
���t��(sh��)��(j��)��ָ:
�ڮ�(d��ng)ǰ���ڡ����O(sh��)���ڷ�����10-15���ѽ�(j��ng)Ӌ(j��)��֮��,�ց���һ������ԓ���ڵĔ�(sh��)��(j��)�����O(sh��)�¼��r(sh��)�g��13��,�@�r(sh��)���ԕ��|�l(f��) Window ����,�@�N��(sh��)��(j��)�ͷQ�����t��(sh��)��(j��)��
��ô���}����,���t�r(sh��)�g��ôӋ(j��)����?
���O(sh��)���ڷ�����10-15,���t�r(sh��)�g��2s,�tֻҪ WaterMark<15+2,���Ҍ���ԓ����,�����|�l(f��) Window ���������������һ�l��(sh��)��(j��)ʹ�� WaterMark>=15+2,10-15�@�����ھͲ������|�l(f��) Window ����,��ʹ���Ĕ�(sh��)��(j��)�� Event Time �����@�����ڕr(sh��)�g��(n��i) ��

 ����
����
�l(f��)���uՓ
���
�֙C(j��)
�(y��n)�C�a
������䛼����L������OFweek����(w��)
߀���Ǖ��T�����M(f��i)ע��
��ӛ�ܴaՈݔ���uՓ��(n��i)��...
Ոݔ���uՓ/�uՓ�L��6~500����

�DƬ��
-
����AI�g�[�����Ј���η���(y��ng)��(qi��ng)�ң�")
OpenAI�l(f��)����AI�g�[�����Ј���η���(y��ng)��(qi��ng)�ң�
-
�������؆���(chu��ng)ʼ��ģʽ")
�R���ط�һ������(zh��n)�������؆���(chu��ng)ʼ��ģʽ
-
���ˊW�\(y��n)����(zh��n)��(b��o)�����C(j��)����ժ�����칤Ultra������λ�������w�ˡ�")
�C(j��)���ˊW�\(y��n)����(zh��n)��(b��o)�����C(j��)����ժ�����칤Ultra������λ�������w�ˡ�
-

�惦Ȧ���ܣ����������V�۾S�����r121�f
-

�L����܇ĸ��˾ͻȻ�������ġ��Ї��L�����������¿Ƽ���
-
؟(z��)�ˆ�ľ��܉BP���m(x��)�������o��")
����ǰؓ(f��)؟(z��)�ˆ�ľ��܉BP���m(x��)�������o��
-
AI Labؓ(f��)؟(z��)���ж�κ�Ƹ��Seed�M(j��n)���{(di��o)����")
�ֹ�(ji��)AI Labؓ(f��)؟(z��)���ж�κ�Ƹ��Seed�M(j��n)���{(di��o)����
-
")
�T���ֹɱ��ף��V�������o���ؑ�(y��ng)
���»������
-
11��7���������u>> ���u�x���S�Ʊ���OFweek 2025����ʮ�ã���(li��n)�W(w��ng)�ИI(y��)����u�x
-
11��20��������(b��o)��>> �����M(f��i)���d��RISC-VоƬ�l(f��)չ�F(xi��n)���c�yԇ����(zh��n)-��Ƥ��
-
����-11.25�������d>>> �M(f��i)˹�а�Ƥ�������ԣ���܇���a(ch��n)δ�����P(gu��n)�I��
-
11��27��������(b��o)��>> �����̎�ϵ�С���܇��Ӽ��g(sh��)�ھ����
-
11��28���������d>> ����Ƥ��������(zh��n)���� �o���ƿء���283FC�����ԙz�f�ñ�
-
12��18��������(b��o)��>> �������h��OFweek 2025����ʮ�ã���(li��n)�W(w��ng)�a(ch��n)�I(y��)���
���]���}
�п������l�O(sh��)��yԇ")
LED����ϵ�y(t��ng)�����I(l��ng)δ��څ����(bi��o)�U")
�W(w��ng)չ������վ")
��ҕ�X�(xi��ng)Ŀ�ټ���")
- 1 ��˹�����˱����ϙC(j��)���˴���������r3.6�|
- 2 ������ҕ��(sh��)��ϵ�y(t��ng)���ύ������ؑc�������D(zhu��n)վ����
- 3 AI �r(sh��)�����������뮔(d��ng)������ �����l�ǡ��O������
- 4 ���c(di��n)�������R���I(l��ng)�ܹ��ء���˹�D���~��һ���r(sh��)�_(d��)�����x��Ť̝��ӯ
- 5 L3�Ԅ��{����ڣ��Ƴ�܇���g(sh��)������̭
- 6 �[��4���һ�Q���`�F(xi��n)������(li��n)�W(w��ng)���������w����
- 7 �C(j��)����9�´��¼���3�҇��a(ch��n)�C(j��)���˛_��IPO���ИI(y��)�����c���Y�ل�(chu��ng)�¸ߣ�
- 8 7���C(j��)���˴�ţ�ɣ��߹ܹɖ|�F(xi��n)VS�C(j��)��(g��u)���ͱ��F(tu��n)��ԓ���l��
- 9 �˲��T(li��n)�ַ���L3�Ԅ��{���^�_ʼƴ���f�|�Ј���
- 10 ���|�ؑ�(y��ng)��܇����������h(hu��n)��(ji��)���c�V�����o���Y��˾����


