









使用 Google Colab 訓(xùn)練的圖像分類模型
介紹
圖像分類是按照預(yù)先確定的原則對圖像內(nèi)的像素組進行分類和識別的過程。在創(chuàng)建分類規(guī)則時使用一種或多種光譜或文本質(zhì)量是可行的。兩種流行的分類技術(shù)是“有監(jiān)督的”和“無監(jiān)督的”。

圖像分類如何工作?
使用標(biāo)記的樣本照片,訓(xùn)練模型以檢測目標(biāo)類別(要在圖像中識別的對象)。監(jiān)督學(xué)習(xí)的一個例子是圖像分類。原始像素數(shù)據(jù)是早期計算機視覺算法的唯一輸入。
然而,單獨的像素數(shù)據(jù)并不能提供足夠一致的表示來包含圖像中表示的項目的許多振蕩。對象的位置、其背景、環(huán)境照明、相機角度和相機焦距都會影響原始像素數(shù)據(jù)。
傳統(tǒng)的計算機視覺模型添加了源自像素數(shù)據(jù)的新組件,例如紋理、顏色直方圖和形狀,以更靈活地對對象進行建模。這種方法的缺點是特征工程變得非常耗時,因為需要更改大量輸入。
哪些色調(diào)對貓的分類至關(guān)重要?形狀的定義應(yīng)該有多靈活?由于特征必須精確地調(diào)整,因此很難創(chuàng)建穩(wěn)健的模型。
訓(xùn)練圖像分類模型
本教程使用了一個基本的機器學(xué)習(xí)工作流程:
· 分析數(shù)據(jù)集
· 創(chuàng)建輸入管道
· 建立模型
· 訓(xùn)練模型
· 分析模型
設(shè)置和導(dǎo)入 TensorFlow 和其他庫
import itertools
import os
import matplotlib.pylab as plt
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
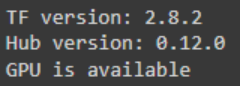
print("TF version:", tf.__version__)
print("Hub version:", hub.__version__)
print("GPU is", "available" if tf.config.list_physical_devices('GPU') else "NOT AVAILABLE")
輸出如下所示:
選擇要使用的 TF2 Saved Model Module
請注意,TF1 Hub 格式的模型在這里不起作用。
有許多模型可以工作。只需從下面單元格中的列表中選擇一個不同的選項,然后繼續(xù)使用Notebook。
在這里,我選擇 了 Inception_v3 并自動從下面的列表中選擇圖像大小為299 x 299。
model_name = "resnet_v1_50" # @param ['efficientnetv2-s', 'efficientnetv2-m', 'efficientnetv2-l', 'efficientnetv2-s-21k', 'efficientnetv2-m-21k', 'efficientnetv2-l-21k', 'efficientnetv2-xl-21k', 'efficientnetv2-b0-21k', 'efficientnetv2-b1-21k', 'efficientnetv2-b2-21k', 'efficientnetv2-b3-21k', 'efficientnetv2-s-21k-ft1k', 'efficientnetv2-m-21k-ft1k', 'efficientnetv2-l-21k-ft1k', 'efficientnetv2-xl-21k-ft1k', 'efficientnetv2-b0-21k-ft1k', 'efficientnetv2-b1-21k-ft1k', 'efficientnetv2-b2-21k-ft1k', 'efficientnetv2-b3-21k-ft1k', 'efficientnetv2-b0', 'efficientnetv2-b1', 'efficientnetv2-b2', 'efficientnetv2-b3', 'efficientnet_b0', 'efficientnet_b1', 'efficientnet_b2', 'efficientnet_b3', 'efficientnet_b4', 'efficientnet_b5', 'efficientnet_b6', 'efficientnet_b7', 'bit_s-r50x1', 'inception_v3', 'inception_resnet_v2', 'resnet_v1_50', 'resnet_v1_101', 'resnet_v1_152', 'resnet_v2_50', 'resnet_v2_101', 'resnet_v2_152', 'nasnet_large', 'nasnet_mobile', 'pnasnet_large', 'mobilenet_v2_100_224', 'mobilenet_v2_130_224', 'mobilenet_v2_140_224', 'mobilenet_v3_small_100_224', 'mobilenet_v3_small_075_224', 'mobilenet_v3_large_100_224', 'mobilenet_v3_large_075_224']
model_handle_map = {
"efficientnetv2-s": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_s/feature_vector/2",
"efficientnetv2-m": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_m/feature_vector/2",
"efficientnetv2-l": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_l/feature_vector/2",
"efficientnetv2-s-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_s/feature_vector/2",
"efficientnetv2-m-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_m/feature_vector/2",
"efficientnetv2-l-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_l/feature_vector/2",
"efficientnetv2-xl-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_xl/feature_vector/2",
"efficientnetv2-b0-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_b0/feature_vector/2",
"efficientnetv2-b1-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_b1/feature_vector/2",
"efficientnetv2-b2-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_b2/feature_vector/2",
"efficientnetv2-b3-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_b3/feature_vector/2",
"efficientnetv2-s-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_s/feature_vector/2",
"efficientnetv2-m-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_m/feature_vector/2",
"efficientnetv2-l-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_l/feature_vector/2",
"efficientnetv2-xl-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_xl/feature_vector/2",
"efficientnetv2-b0-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_b0/feature_vector/2",
"efficientnetv2-b1-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_b1/feature_vector/2",
"efficientnetv2-b2-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_b2/feature_vector/2",
"efficientnetv2-b3-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_b3/feature_vector/2",
"efficientnetv2-b0": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_b0/feature_vector/2",
"efficientnetv2-b1": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_b1/feature_vector/2",
"efficientnetv2-b2": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_b2/feature_vector/2",
"efficientnetv2-b3": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_b3/feature_vector/2",
"efficientnet_b0": "https://tfhub.dev/tensorflow/efficientnet/b0/feature-vector/1",
"efficientnet_b1": "https://tfhub.dev/tensorflow/efficientnet/b1/feature-vector/1",
"efficientnet_b2": "https://tfhub.dev/tensorflow/efficientnet/b2/feature-vector/1",
"efficientnet_b3": "https://tfhub.dev/tensorflow/efficientnet/b3/feature-vector/1",
"efficientnet_b4": "https://tfhub.dev/tensorflow/efficientnet/b4/feature-vector/1",
"efficientnet_b5": "https://tfhub.dev/tensorflow/efficientnet/b5/feature-vector/1",
"efficientnet_b6": "https://tfhub.dev/tensorflow/efficientnet/b6/feature-vector/1",
"efficientnet_b7": "https://tfhub.dev/tensorflow/efficientnet/b7/feature-vector/1",
"bit_s-r50x1": "https://tfhub.dev/google/bit/s-r50x1/1",
"inception_v3": "https://tfhub.dev/google/imagenet/inception_v3/feature-vector/4",
"inception_resnet_v2": "https://tfhub.dev/google/imagenet/inception_resnet_v2/feature-vector/4",
"resnet_v1_50": "https://tfhub.dev/google/imagenet/resnet_v1_50/feature-vector/4",
"resnet_v1_101": "https://tfhub.dev/google/imagenet/resnet_v1_101/feature-vector/4",
"resnet_v1_152": "https://tfhub.dev/google/imagenet/resnet_v1_152/feature-vector/4",
"resnet_v2_50": "https://tfhub.dev/google/imagenet/resnet_v2_50/feature-vector/4",
"resnet_v2_101": "https://tfhub.dev/google/imagenet/resnet_v2_101/feature-vector/4",
"resnet_v2_152": "https://tfhub.dev/google/imagenet/resnet_v2_152/feature-vector/4",
"nasnet_large": "https://tfhub.dev/google/imagenet/nasnet_large/feature_vector/4",
"nasnet_mobile": "https://tfhub.dev/google/imagenet/nasnet_mobile/feature_vector/4",
"pnasnet_large": "https://tfhub.dev/google/imagenet/pnasnet_large/feature_vector/4",
"mobilenet_v2_100_224": "https://tfhub.dev/google/imagenet/mobilenet_v2_100_224/feature_vector/4",
"mobilenet_v2_130_224": "https://tfhub.dev/google/imagenet/mobilenet_v2_130_224/feature_vector/4",
"mobilenet_v2_140_224": "https://tfhub.dev/google/imagenet/mobilenet_v2_140_224/feature_vector/4",
"mobilenet_v3_small_100_224": "https://tfhub.dev/google/imagenet/mobilenet_v3_small_100_224/feature_vector/5",
"mobilenet_v3_small_075_224": "https://tfhub.dev/google/imagenet/mobilenet_v3_small_075_224/feature_vector/5",
"mobilenet_v3_large_100_224": "https://tfhub.dev/google/imagenet/mobilenet_v3_large_100_224/feature_vector/5",
"mobilenet_v3_large_075_224": "https://tfhub.dev/google/imagenet/mobilenet_v3_large_075_224/feature_vector/5",
}
model_image_size_map = {
"efficientnetv2-s": 384,
"efficientnetv2-m": 480,
"efficientnetv2-l": 480,
"efficientnetv2-b0": 224,
"efficientnetv2-b1": 240,
"efficientnetv2-b2": 260,
"efficientnetv2-b3": 300,
"efficientnetv2-s-21k": 384,
"efficientnetv2-m-21k": 480,
"efficientnetv2-l-21k": 480,
"efficientnetv2-xl-21k": 512,
"efficientnetv2-b0-21k": 224,
"efficientnetv2-b1-21k": 240,
"efficientnetv2-b2-21k": 260,
"efficientnetv2-b3-21k": 300,
"efficientnetv2-s-21k-ft1k": 384,
"efficientnetv2-m-21k-ft1k": 480,
"efficientnetv2-l-21k-ft1k": 480,
"efficientnetv2-xl-21k-ft1k": 512,
"efficientnetv2-b0-21k-ft1k": 224,
"efficientnetv2-b1-21k-ft1k": 240,
"efficientnetv2-b2-21k-ft1k": 260,
"efficientnetv2-b3-21k-ft1k": 300,
"efficientnet_b0": 224,
"efficientnet_b1": 240,
"efficientnet_b2": 260,
"efficientnet_b3": 300,
"efficientnet_b4": 380,
"efficientnet_b5": 456,
"efficientnet_b6": 528,
"efficientnet_b7": 600,
"inception_v3": 299,
"inception_resnet_v2": 299,
"nasnet_large": 331,
"pnasnet_large": 331,
}
model_handle = model_handle_map.get(model_name)
pixels = model_image_size_map.get(model_name, 224)
print(f"Selected model: {model_name} : {model_handle}")
IMAGE_SIZE = (pixels, pixels)
print(f"Input size {IMAGE_SIZE}")
BATCH_SIZE = 16#@param {type:"integer"}
輸入為所選模塊正確縮放。更大的數(shù)據(jù)集有助于訓(xùn)練,尤其是在微調(diào)時(即每次讀取圖像時圖像的隨機失真)。
我們的數(shù)據(jù)集應(yīng)該如下圖所示進行組織。

我們的自定義數(shù)據(jù)集現(xiàn)在必須上傳到云端硬盤。一旦我們的數(shù)據(jù)集需要擴充,我們必須將數(shù)據(jù)擴充參數(shù)設(shè)置為 true。
data_dir = "/content/Images"
def build_dataset(subset):
return tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=.10,subset=subset,label_mode="categorical",seed=123,image_size=IMAGE_SIZE,batch_size=1)
train_ds = build_dataset("training")
class_names = tuple(train_ds.class_names)
train_size = train_ds.cardinality().numpy()
train_ds = train_ds.unbatch().batch(BATCH_SIZE)
train_ds = train_ds.repeat()
normalization_layer = tf.keras.layers.Rescaling(1. / 255)
preprocessing_model = tf.keras.Sequential([normalization_layer])
do_data_augmentation = False #@param {type:"boolean"}
if do_data_augmentation:
preprocessing_model.a(chǎn)dd(tf.keras.layers.RandomRotation(40))
preprocessing_model.a(chǎn)dd(tf.keras.layers.RandomTranslation(0, 0.2))
preprocessing_model.a(chǎn)dd(tf.keras.layers.RandomTranslation(0.2, 0))
# Like the old tf.keras.preprocessing.image.ImageDataGenerator(),
# image sizes are fixed when reading, and then a random zoom is applied.
# RandomCrop with a batch size of 1 and rebatch later.
preprocessing_model.a(chǎn)dd(tf.keras.layers.RandomZoom(0.2, 0.2))
preprocessing_model.a(chǎn)dd(tf.keras.layers.RandomFlip(mode="horizontal"))
train_ds = train_ds.map(lambda images, labels:(preprocessing_model(images), labels))
val_ds = build_dataset("validation")
valid_size = val_ds.cardinality().numpy()
val_ds = val_ds.unbatch().batch(BATCH_SIZE)
val_ds = val_ds.map(lambda images, labels:(normalization_layer(images), labels))
輸出:

定義模型
所需要做的就是使用 Hub 模塊在特征提取器層之上分層線性分類器。
我們最初使用不可訓(xùn)練的特征提取器層來提高速度,但你也可以啟用微調(diào)以獲得更好的精度。
do_fine_tuning = True
print("Building model with", model_handle)
model = tf.keras.Sequential([
# Explicitly define the input shape so the model can be properly
# loaded by the TFLiteConverter
tf.keras.layers.InputLayer(input_shape=IMAGE_SIZE + (3,)),
hub.KerasLayer(model_handle),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(len(class_names),activation='sigmoid',
kernel_regularizer=tf.keras.regularizers.l2(0.0001))
])
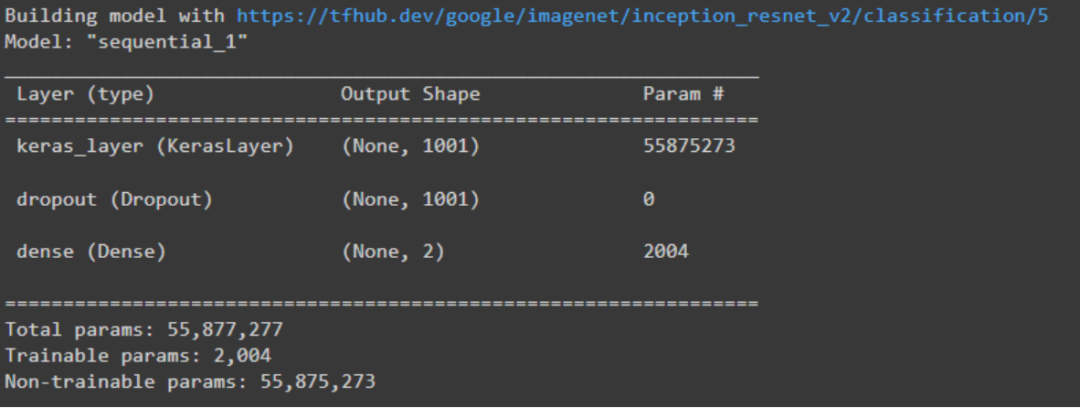
model.build((None,)+IMAGE_SIZE+(3,))
model.summary()
輸出如下
模型訓(xùn)練
model.compile(
optimizer=tf.keras.optimizers.SGD(learning_rate=0.005, momentum=0.9),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True, label_smoothing=0.1),
metrics=['accuracy'])
steps_per_epoch = train_size // BATCH_SIZE
validation_steps = valid_size // BATCH_SIZE
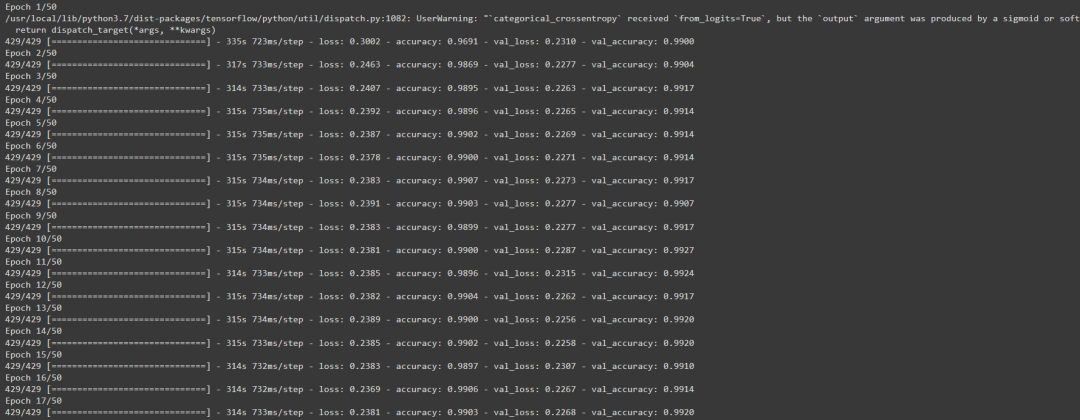
hist = model.fit(
train_ds,
epochs=50, steps_per_epoch=steps_per_epoch,
validation_data=val_ds,
validation_steps=validation_steps).history
輸出如下所示:
訓(xùn)練完成后,我們需要使用以下代碼保存模型:
model.save ("save_locationmodelname.h5")
結(jié)論
這篇博文使用卷積神經(jīng)網(wǎng)絡(luò)(CNN) 根據(jù)圖片的視覺內(nèi)容對圖片進行分類。該數(shù)據(jù)集用于測試和訓(xùn)練 CNN。其準確率大于 98%。我們必須使用微小的灰度圖像作為我們的教學(xué)資源。與其他常規(guī) JPEG 照片相比,這些照片需要大量的處理時間。用于在 GPU 集群上訓(xùn)練網(wǎng)絡(luò)的具有更多層和更多圖片數(shù)據(jù)的模型將更準確地對圖像進行分類。未來的發(fā)展將集中在對圖像分割過程非常有用的巨大彩色圖像的分類上。
關(guān)鍵要點
· 圖像分類是計算機視覺的一個分支,它使用一組經(jīng)過算法訓(xùn)練的指定標(biāo)簽或類別對圖像內(nèi)的像素或矢量集進行分類和標(biāo)記。
· 可以區(qū)分有監(jiān)督和無監(jiān)督分類。
· 在監(jiān)督分類中,分類算法使用一組圖像及其相關(guān)標(biāo)簽進行訓(xùn)練。
· 無監(jiān)督分類算法僅使用原始數(shù)據(jù)進行訓(xùn)練。
· 你需要大量具有準確標(biāo)記數(shù)據(jù)的數(shù)據(jù)集來創(chuàng)建值得信賴的圖片分類器。
原文標(biāo)題 : 使用 Google Colab 訓(xùn)練的圖像分類模型

 分享
分享
請輸入評論內(nèi)容...
請輸入評論/評論長度6~500個字

布的AI瀏覽器,市場為何反應(yīng)強烈?")
,阿里重啟創(chuàng)始人模式")
報:宇樹機器人摘下首金,天工Ultra搶走首位“百米飛人”")


人喬木出軌BP后續(xù):均被辭退")
AI Lab負責(zé)人李航卸任后返聘,Seed進入調(diào)整期")
")
最新活動更多
-
11月7日立即參評>> 【評選】維科杯·OFweek 2025(第十屆)物聯(lián)網(wǎng)行業(yè)年度評選
-
11月20日立即報名>> 【免費下載】RISC-V芯片發(fā)展現(xiàn)狀與測試挑戰(zhàn)-白皮書
-
即日-11.25立即下載>>> 費斯托白皮書《柔性:汽車生產(chǎn)未來的關(guān)鍵》
-
11月27日立即報名>> 【工程師系列】汽車電子技術(shù)在線大會
-
11月28日立即下載>> 【白皮書】精準洞察 無線掌控——283FC智能自檢萬用表
-
12月18日立即報名>> 【線下會議】OFweek 2025(第十屆)物聯(lián)網(wǎng)產(chǎn)業(yè)大會
推薦專題
備測試")
先進LED照明系統(tǒng),引領(lǐng)未來趨勢新標(biāo)桿")
網(wǎng)展·深圳站")

- 1 特斯拉工人被故障機器人打成重傷,索賠3.6億
- 2 AI 時代,阿里云想當(dāng)“安卓” ,那誰是“蘋果”?
- 3 拐點已至!匯川領(lǐng)跑工控、埃斯頓份額第一、新時達海爾賦能扭虧為盈
- 4 L3自動駕駛延期,逼出車企技術(shù)自我淘汰
- 5 隱退4年后,張一鳴久違現(xiàn)身!互聯(lián)網(wǎng)大佬正集體殺回
- 6 機器人9月大事件|3家國產(chǎn)機器人沖刺IPO,行業(yè)交付與融資再創(chuàng)新高!
- 7 谷歌“香蕉”爆火啟示:國產(chǎn)垂類AI的危機還是轉(zhuǎn)機?
- 8 7倍機器人大牛股:高管股東套現(xiàn)VS機構(gòu)兇猛抱團,該信誰?
- 9 八部門聯(lián)手放行L3自動駕駛!巨頭開始拼搶萬億市場?
- 10 OpenAI發(fā)布的AI瀏覽器,市場為何反應(yīng)強烈?

- 高級軟件工程師 廣東省/深圳市
- 自動化高級工程師 廣東省/深圳市
- 光器件研發(fā)工程師 福建省/福州市
- 銷售總監(jiān)(光器件) 北京市/海淀區(qū)
- 激光器高級銷售經(jīng)理 上海市/虹口區(qū)
- 光器件物理工程師 北京市/海淀區(qū)
- 激光研發(fā)工程師 北京市/昌平區(qū)
- 技術(shù)專家 廣東省/江門市
- 封裝工程師 北京市/海淀區(qū)
- 結(jié)構(gòu)工程師 廣東省/深圳市

